Machine learning can change the way institutions operate

Key takeaways
- Machine learning automates laborious programming, unlocks insights, and enables smarter decision-making
- Machine learning offers streamlined operations and potential breakthrough insights for recruitment and retention
- Recruitment and academic advising are two areas ripe for more immediate application of machine learning
There is a lot of buzz about the benefits as well as the risks of artificial intelligence (AI) and machine learning. Does machine learning deserve the hype? Yes, and I’m excited to share how it can improve institutional enrollment and retention.
What is machine learning and how does it work?
Machine learning is an application of artificial intelligence that helps machines learn rules themselves instead of only operating according to pre-programmed rules. In this way, it’s a program that learns and refines its own processes. This enables programmers to not worry about creating complex business rules, rather they can concentrate on preparing the data sets that, through machine learning, will produce the most robust models. When programmers have less legwork, they have more time for more strategic tasks.
In traditional programming, the logic of operations was hard-coded into the program and the program executed as per the rules that governed the logic. All rules were pre-coded. For instance, if I were to write a program that can identify that a given image is a green ball or a purple ball, I would write certain rules based on the pixel values, and the program could identify the color based only on those rules. However, if the images feature a wide range of lighting conditions, then the program’s rules would fail resulting in mistaken identification. I would now need to write new rules to accommodate each unique lighting condition.

Figure 1: Green ball and purple ball
Machine learning solves this problem: a program can be built that learns the rules of differentiating between a green and a purple ball based on various labeled images taken under different lighting conditions. The program forms its own rules based on the image set and will be able to identify whether a given picture is a green ball or a purple ball.
The following illustration outlines one such model. In the chart below, the green dots represent the values of green ball images and purple dots are the values derived from images of the purple ball. A line could be drawn that divides the green and purple dots, providing an easy conclusion as to which is which. The program’s purpose is to determine the line that divides these two sets of dots.
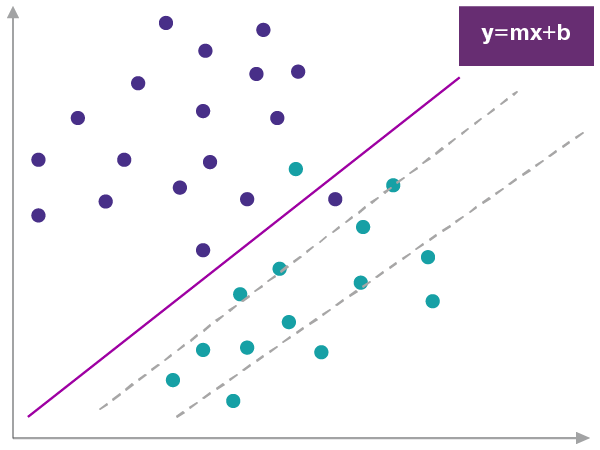
Figure 2: Simple classifier model
Now, if a new image is given, a dot is placed on the chart. Based on its position on either side of the line, the program knows if the dot is green or purple. By making position calculations over time with lots of data inputs, the program is able to determine the color of the ball with minimum error.
You may notice in the image above, there’s one purple dot on the side of green and a green dot in the side of purple, which is an error. So, through a process we might call “teaching” (i.e. training by feeding data to the program), the machine learning program will “learn” to avoid errors without programmers needing to add rule after rule to the underlying code.
To use some of the terms of machine learning, the solid line separating the two colors represents the model, the values of the image (green or purple) are the features, and since the model classifies the input as the green or purple ball it is called the classifier model.
I could use the same program for differentiation between a cat and a dog. I just need to feed in labeled pictures of dogs and cats. The program differentiates between them to the best of its available data.
Figure 3: A typical machine learning program
The process of the algorithm building the model over iterations so that the error of results is minimized is termed “learning”. There are two kinds of learning processes:
- Supervised learning is a process in which the dataset is clearly labeled and the algorithm tries to build the model based on the known feature set. The example of differentiating between the green and the purple ball is a supervised learning process.
- Unsupervised learning is a process by which the algorithm discovers and learns the feature set that affects a particular outcome. For example, grouping customers together based on their buying patterns that may not have been known beforehand.
Both methods of “learning” help establish the strength or prevalence of patterns or trends among inputs, and unsupervised learning also helps users discover such insights.
How can machine learning impact enrollment and retention?
Likely in the next decade, machine learning will become an integral part of practically all everyday operations dealing with data inputs. Machine learning applications leverage data sort of like how a cutting-edge car engine enables a car to travel greater distances at greater speeds on the same amount of fuel—it saves manual programming time and some of the manual labor of crunching analytical meaning.
Here are some of the ways machine learning could begin to improve enrollment and retention operations:
Recruitment
Currently, data-savvy enrollment teams can make smart decisions and adjustments about recruitment campaigns using well-integrated reports. Machine learning can save some of the number-crunching and analysis, by determining yield ratios that help determine prospects who are at risk of not accepting or not progressing through the recruitment funnel. Machine learning can “learn” this information and develop even stronger models for yield rates—based on parameters such as response times, clicks, campus visits, or other direct prospect activities that do or don’t lead to application and enrollment—much earlier in the process, so an enrollment team can take faster, more decisive actions to court prospective students.
Student retention modeling
Early alert systems give administrators a chance to increase engagement with students at risk of failing, losing funding, or dropping out altogether. Machine learning can help to identify students at risk based on numerous parameters derived from student data faster than institutions currently can. They can build and continuously improve mathematical student success models based on the results obtained—in the short term, it can help institutions devise more accurate indicator criteria for at-risk students. And in the long-term, it will help produce potentially revolutionary retention models that help administrators draw conclusions about what really helps all kinds of students persist all the way from acceptance to graduation.
Academic advising
Students in many cases don’t seek out advice on the best path to a degree from their advisors, or may not always get the advice they need most—often because they may not have the time, or they may not know they’re even in need of support (or what the right support would be). Machine learning can discover connections or patterns using student data that could indicate the ideal action for an advisor or student success specialist to reach out with—or, instead of only initiating an early alert, chatbot programs powered by machine learning could engage students directly in a system that provides tailored support directly to the student.
Imagine a college student receiving a text that not only prompts her to register for classes but suggests a class schedule based on her progress toward her major and the times of day during which she has historically performed well, and spreads out killer courses shown to cause a dip in GPA when taken at the same time. With machine learning and chatbots, this scenario is becoming a reality. See a prototype and learn how intelligent registration can improve student engagement and success, and how institutions can implement these emerging technologies.
Machine learning is ready to help higher ed, when higher ed is ready
Many institutions already implement early alert systems and modern, integrated communications systems that integrate data to enhance their enrollment and retention operations—machine learning represents a way for these operations to work faster and more accurately, enabling even better analytics capabilities.
The really exciting part is how, over time, machine learning-derived outcomes used to inform enrollment and retention could greatly complement an institution’s effort to discover breakthrough models for student success after graduation, in the form of career success modeling.
However, progress in this direction requires some risk-taking at institutions and continued, steady operational efficiency often gained through digital and data-driven campus transformations. Machine learning, like any new technology, will only work as well as the systems and people prepared to run them.
If implemented safely and thoughtfully, machine learning applications can uncover insights institutions couldn’t see before, or at rates that were once impossible. It’s also important to remember data-based results function best like a compass guiding users in the right direction. Time saved in computing data-based insights enables leaders to make faster, more informed decisions. Machine learning won’t make decisions for anyone, but it contributes to the wave of innovation helping institutions find their way forward through data.
Meet the authors




